 The Raising of Lazarus The Raising of Lazarus The drug hydroxychloroquine is being tested against COVID19, but there is still no compelling scientific evidence that it works, let alone that it is a “game changer” in our fight against COVID19. However, the president has claimed that there are very strong signs that it works on coronavirus, and the president’s economic adviser, Peter Navarro, has criticized the infectious disease expert, Dr. Anthony Fauci, for questioning alleged evidence hydroxychloroquine works on COVID19. The French researcher, Dr. Didier Raoult, who performed the original trial of hydroxychloroquine that generated all the current interest in the drug, now claims that he has treated 1,000 patients with COVID19 with a 99.3% success rate. In the news, I have read descriptions of patients that have recovered after being administered hydroxychloroquine in what has been called a “Lazarus effect” after the Biblical story where Jesus brought Lazarus back from the dead. So what is a scientist to make of this? I have acknowledged that science cannot operate in a vacuum. I recognize something that Dr. Fauci has also recognized, and that is that people need hope. However, as Dr. Fauci has also stated, scientists have the obligation to subject drugs to well-designed tests that will conclusively answer the question of whether a drug works or not. There seems to be a discrepancy between the quality of the evidence that scientists and non-scientist will accept to declare that a drug works, and there is the need to resolve this discrepancy. People anxiously waiting for evidence regarding whether hydroxychloroquine works, will understandably concentrate on patients that recover. Therefore they are more prone to make positive information the focus of their attention. Any remarkable cases where people recover (Lazarus effects) will invariably be pushed to the forefront of the news, and presented as evidence that the drug works wonders. What people need to understand, is that these “Lazarus” cases always occur, even in the absence of effective interventions. We all react to disease and drugs differently. Someone somewhere will always recover sooner and better than others. How do we know whether one of these Lazarus cases was a real effect of the drug or a happenstance? Isolated cases of patients who get better, no matter how spectacular, are meaningless. Scientists look at people who recover from an illness after being given a drug in the context of the whole population of patients treated with the drug to derive a proportion. The goal is then to compare this proportion to that of a population of patients not given the drug. Scientists also have to consider both positive and negative information. For the purposes of determining whether a drug works, patients that don’t recover are just as important to take into account as those that do. What if a drug benefits some patients to a great extent but kills others? Depending on the condition being treated, it may not be justified to use this drug until you can identify the characteristics of the patients that will be benefited by the drug. To do all the above properly, you need to carry out a clinical trial. No matter how desperate people are, and no matter how angry it makes them to hear otherwise, this is the only way to establish whether a drug works or not. 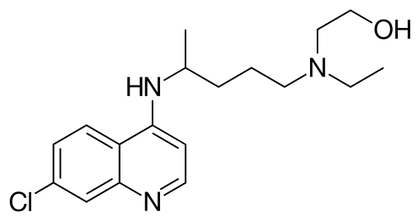 Hydroxychloroquine Hydroxychloroquine Once we accept the need for a clinical trial to establish whether a drug works, another issue is trial design. A trial carried out by scientists is not valid just because it happened. There are optimally-designed trials and suboptimal or poorly designed trials. There are several things a optimally designed trial must have.
1) The problem with much of the evidence regarding hydroxychloroquine is that it has been tested against COVID-19 in very small trials, and clinical trials of small size are notorious for giving inaccurate results. You need a large enough sample size to make sure your results are valid. 2) Another problem is: what you are comparing the drug against? Normally, you give the drug to a group of patients, and you compare the results to another group that simultaneously received an inert dummy pill (a placebo), or at least to a group of patients that received the best available care. This is what is called a control group. In many hydroxychloroquine trials there were no formal control groups, but rather the results were loosely compared to “historical controls”, in other words, to how well a group of patients given no drug fared in the past. But this procedure can be very inaccurate as there is considerable variation in such controls. 3) Another issue is the so called placebo effect. The psychology of patients knowing that they are being given a new potentially lifesaving drug is different from that of patients that are being treated with regular care. Just because of this, the patients being given the drug may experience an improvement (the so called placebo effect). To avoid this bias, the patients and even the attending physicians and nurses are often blinded as to the nature of the treatment in the best trials. Most hydroxychloroquine studies were not performed blind. 4) Even if you are comparing two groups, drug against placebo or best care, you need to allocate the patients to both groups in a random fashion to make sure that you do not end up with a mix of patients in a group that has some characteristic that is overrepresented compared to the other group, as this could influence the results of the trial. Most hydroxychloroquine studies were not randomized. These are but a few factors to consider when performing a trial to determine whether a drug works. These and other factors, if they are not carefully dealt with, can result in a trial yielding biased results that may over or underestimate the effectiveness of a drug. Due to budget constraints, urgency, or other reasons, scientists sometimes carry out very preliminary trials that are not optimal just to give a drug an initial “look see” or to gain experience with the administration of the drug in a clinical setting. But these trials are just that, preliminary, and there is no scientific justification to base any decision regarding the promotion of a drug based on this type of trials. The FDA recently has urged caution against the use of hydroxychloroquine outside the hospital setting due to reports of serious heart rhythm problems in patients with COVID-19 treated with the drug. A recent study with US Veterans who were treated with hydroxychloroquine found a higher death rate among patients who were administered the drug (to be fair, this study was retrospective and therefore did not randomize the allocation of patients to treatments, so this could have biased the results). Even though I am skeptical about this drug, I would rather save lives than be right. I really hope it works, but the general public needs to understand that neither reported Lazarus effects nor suboptimal clinical trials will give us the truth. The 1310-11painting The Raising of Lazarus by Duccio di Buoninsegna is in the public domain. The image of hydroxychloroquine by Fvasconcellos is in the public domain.
0 Comments
 How many times have you read about the results of studies that were claimed to be or not be statistically significant? How many times have you read that the frequency of some occurrence was found or not found to be statistically significantly above chance? It’s like if the phrase “statistically significant” is considered some sort of seal of legitimacy. If it is statistically significant, it must be true, no? And if it is not statistically significant, it must be false, right? The truth, of course, is more complex than that. Let’s address one issue that invalidates many studies regardless of whether their results are statistically significant or not: sample size. Studies conducted with a small sample size, if not carefully designed, are very prone to variability. A very big red flag is when the results of a small study are unexpected. Studies with a small sample size can produce false results either in favor or against the premise that they are addressing, although most of the time they fail to produce statistically significant results for an effect, even if the effect is real. This sample size issue is often not reported when the study is presented in the news or, if reported, it normally goes something like this:
The authors caution that this was a study with a small sample size but (there is always a “but”) if this result can be repeated in a larger study then… On the one hand, the authors acknowledge that the results of the study may be bogus due to the small sample size, but on the other hand the authors nevertheless find the results worthy enough to publicize or to acquiesce to the desire of journalists to publicize them! So, are all studies with a small sample size bad, and should be avoided? Not necessarily. Sometimes scientists perform small studies intended to give the issue being tested a “look-see”. Sometimes studies with small sample sizes are all that is possible to do due to budgetary constraints or other constraints such a working with a rare disease. Scientists also perform small studies to gain experience in order to later design larger studies. But there is another reason a study with a small sample size may be justified. Consider the following statistical joke: A scientist asks a group of 3 students to concentrate in teleporting through a solid wall. Of these 3 students one manages to accomplish this feat. Excitedly the scientist informs a colleague of the results of the experiment, but his colleague dismisses it outright arguing that with a sample size of 3 you cannot possibly obtain any statistically significant results. The premise of this joke is that one person achieving such a feat would be enough. No further sample (or even statistics for that matter) is required! This is intended to illustrate that the nature of the effect being evaluated is important. If scientists are only interested in detecting a very large effect, then a study with a small sample size may be totally justified. But you may argue that a study with a large sample size is always more desirable, no? After all, you can’t go wrong if you perform a study with a large sample size, right? Not only are studies with large sample sizes more expensive, time-consuming, and difficult to implement, but there is a seldom discussed and surprising downside to large samples sizes illustrated in the following example: A researcher spends several years performing trials to evaluate whether human subjects can mentally affect the outcome of the toss of a coin as simulated by a computer. After accumulating and analyzing hundreds of thousands of trials, the researcher finds that human subjects can influence the computer mentally to produce heads as oppose to tails with a frequency of 50.0001%, and that this effect is statistically significantly above mere chance. The problem outlined in the example above, is that using a very large sample size you can detect anything, including random background fluctuations or equipment calibration imperfections, as statistically significant. Detecting such a small effect, regardless of whether it is statistically significant or not, may not only be meaningless, but is also devoid of any practical significance. The dirty little secret of statistical analysis is that statistical significance cannot replace good judgement. Before a study, you have to ask what is the size of the effect that you want to detect and whether it would be of importance to detect an effect of that magnitude, if indeed it is present. These questions will lead to determining the correct sample size for the study, and in fact whether the study should be performed at all! To recap and answer the question posited in the title of this post: in statistics whether sample size matters or not depends on the magnitude and importance of the effect being evaluated. 1) The detection of an important small effect may require a study with a large sample size. 2) The detection of an important large effect may be achieved with a carefully designed study employing a small sample size. 3) The detection of a small effect with a large sample size may be irrelevant if the effect is not important, regardless of statistical significance. 4) The detection of an effect with a small sample size in a study not carefully designed is likely to be a happenstance occurrence, regardless of statistical significance. So next time you hear about whether something was statistically significant, inquire about sample size. Image by Nick Youngson used here under an Attribution-ShareAlike 3.0 Unported (CC BY-SA 3.0) license. |
Categories
All
Archives
June 2024
|
 RSS Feed
RSS Feed